工作每天都會看生產數據,測試數據量大且接近常態分佈,看看平均值 (u)與標準差(s)就可以大概了解整個數據的分佈狀況,99.7%的數據都會落在u±s內。







最後整理一下就可以得到最後的結果,後來交叉查詢資料有看到YouTube上面的高中數學[3]有完整的推導,也可以參考一下。

這樣如果我們知道有分別兩筆統計資料,分別知道每筆資料的統計數量n, 平均數u與標準差std:
第一筆:n=15、平均數4.25、標準差STD 2.64
第二筆:n=12、平均數14.25、標準差STD 2.64
只看這兩筆資料的平均數與標準差可以畫出分佈圖如下,計算合併後的平均數也很直觀:
u=[1/(15+12)]*[15*4.25+12*14.25]

然後可以透過公式計算出合併後的方差與標準差為:
方差: 31.71
標準差: 5.63
如果把合併後的統計資料與原本兩個資料放在一起比較就會類似下圖分佈。

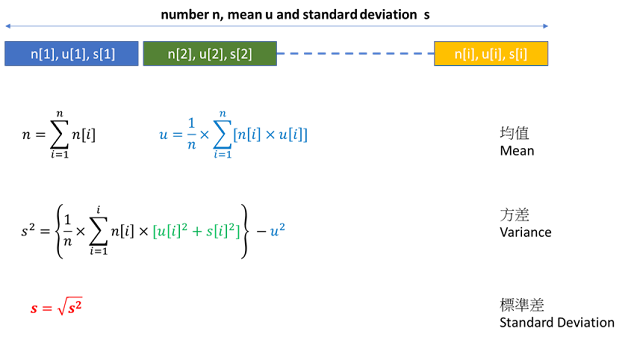
其實從公式中你也可以達到多筆統計資料的合併公式,為了方便呈現公式這裡改成第一筆資料數量n[1], 平均數為u[1],
標準差為s[1],所以第二筆為n[2], u[2], s[2]以此類推,合併後的公式可以兼化成如下。

參考資料
[1] Wikipedia, Pooled variance
https://en.wikipedia.org/wiki/Pooled_variance
[2] eMathZone, Combined Variance
https://www.emathzone.com/tutorials/basic-statistics/combined-variance.html
[3] YouTube, 高中數學免費線上學習網, “B2---4--1----範例9----已知兩組資料的平均與標準差求合併後的平均與標準差”
https://www.youtube.com/watch?v=BxyGU1hwtLU



